A Data Structure is a way of organizing and storing a collection of data elements in a structured manner so that it can be accessed and modified efficiently.
For example:
When there is only one student, the data such as name, age, and roll number can be stored easily. For example, a student named Pawan has Name = “Pawan”, Age = 17, and Class = 4. Even simple storage methods are enough for managing such small data.
However, when there are hundreds or thousands of students, manual or simple storage methods become inefficient. In such cases, Data Structures are required to organize the records properly. They help in:
- Fast searching of student records
- Easy insertion of new data
- Easy deletion and updating of records
- Efficient use of memory
Therefore, Data Structures like Arrays, Lists, or Files are useful for both small and large amounts of data, but they are most important when handling large data sets.
What is Data Structure?
In simple words, a Data Structure is a structured way of storing data in an ordered and organized form so that operations such as searching, insertion, deletion, and updating can be done efficiently. A well-designed data structure increases efficiency and reduces complexity.
You can also remember it as, Data Structures allow us to store information in such a way that it can be created, viewed, processed, and managed easily.
Types of Data Structures
1. Arrays
An array is a data structure that stores multiple values of the same data type in continuous memory locations. Because all elements are stored together, the memory address of any element can be easily calculated using the base address of the array.
Each element in an array is identified by an index, which always starts from 0.
Example:
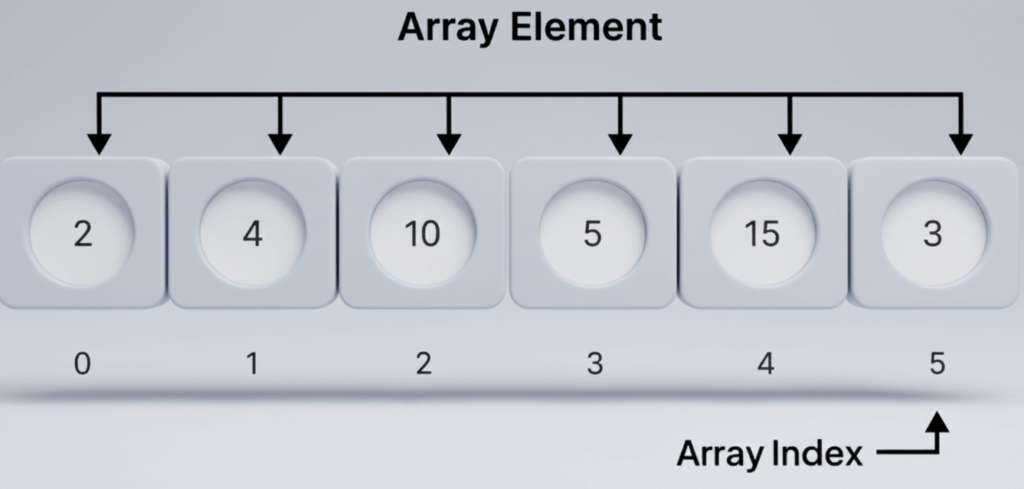
Consider an array [2, 4, 10, 5, 15, 3]. Here, 2 is at index 0, 4 at index 1, and so on. Accessing index 2 returns 10.
2. Stacks
A stack is a linear data structure that follows the LIFO (Last In, First Out) or FILO (First In, Last Out) principle.
This means the last element inserted (pushed) into the stack is the first one removed (popped).
A stack mainly supports two basic operations:
- Push – to insert an element into the stack
- Pop – to remove the top element from the stack
The stack allows insertion and deletion only from one end, called the top.
Example:
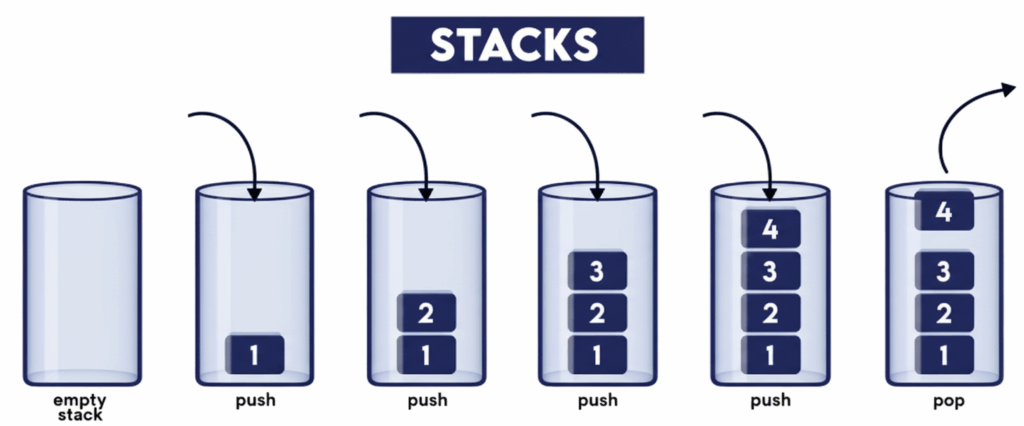
Initially the stack is empty. After pushing 1, 2, 3, 4, the top element becomes 4. When we perform a pop, 4 is removed first.
3. Queues
A queue is a linear data structure that follows the FIFO (First In, First Out) principle.
This means the first element added to the queue is the first one removed.
In a queue:
- Elements are inserted at the rear (enqueue)
- Elements are removed from the front (dequeue)
It works just like a line of people waiting for their turn, where the person who comes first is served first.
Example:
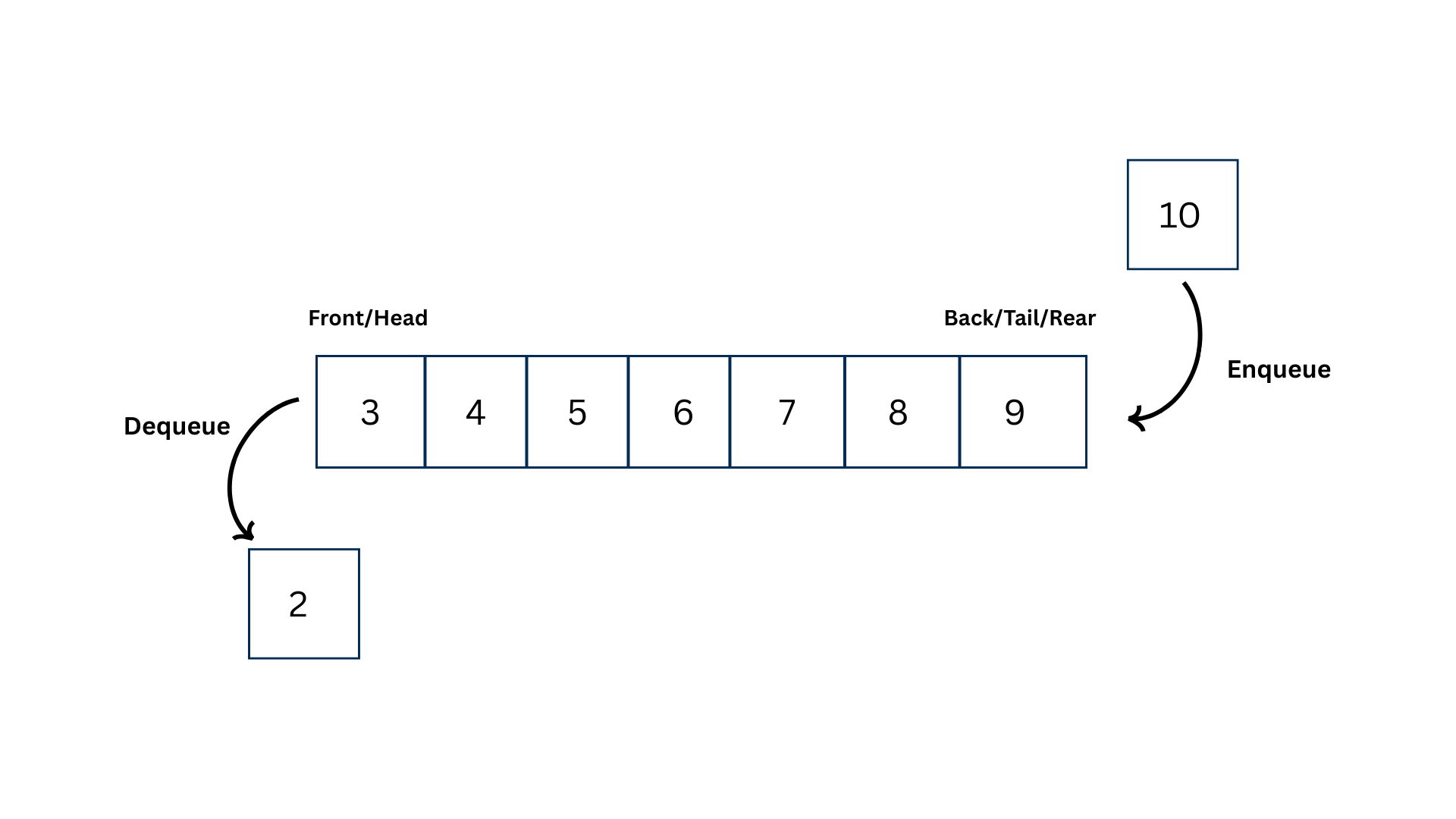
The queue contains elements 2, 3, 4, 5, 6, 7, 8, 9. A new element 10 is added at the rear, and the element 2 is removed from the front.
4. Linked Lists
A linked list is a linear data structure that stores elements in non-contiguous memory locations.
Each element is called a node, and every node contains two parts:
- Data – the value to be stored
- Link (reference) – the address of the next node
The nodes are connected using these links, forming a chain. The last node points to NULL, which indicates the end of the linked list.
Example:
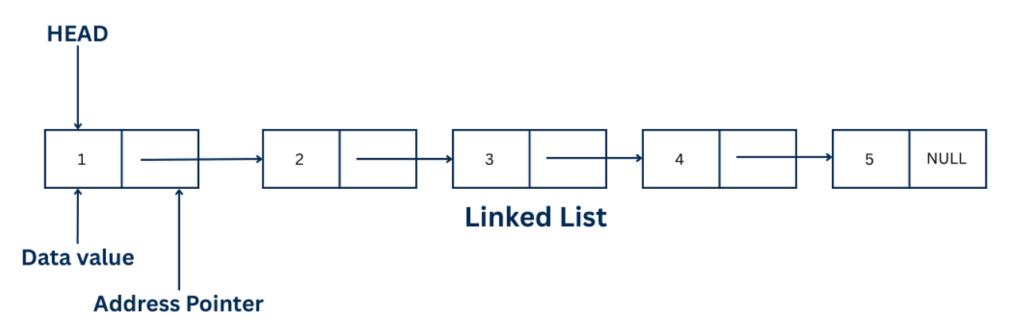
The first node stores 1 and its next pointer refers to the next node storing 2, and so on. The last node points to NULL. The first node is accessed through Head.
5. Trees
A tree is a non-linear, hierarchical data structure used to represent parent-child relationships.
It starts with a root node, from which other nodes, called child nodes, branch out.
In a tree:
- Each node has only one parent, except the root node, which has no parent
- Nodes that do not have any children are called leaf nodes
Trees are commonly used to represent structures like file systems, organization charts, and family trees.
Example:
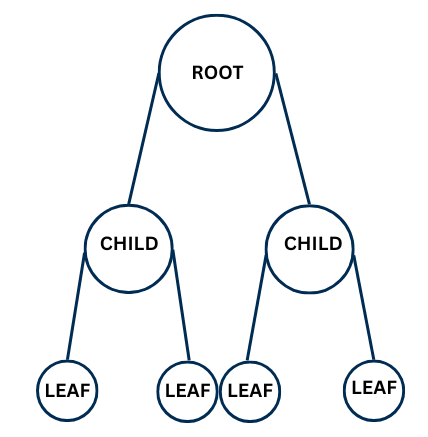
The root node has 2 children, and each child has 2 leaf nodes. Nodes with no children are leaf nodes.
6. Graphs
A graph is a non-linear data structure consisting of nodes (vertices) and edges.
Vertices represent entities, and edges represent the relationships or connections between them.
Graphs are widely used to model real-world networks, such as:
- Social networks
- Transportation systems
- Computer and communication networks
Graphs can be directed or undirected, depending on whether the connections have a direction.
Example:
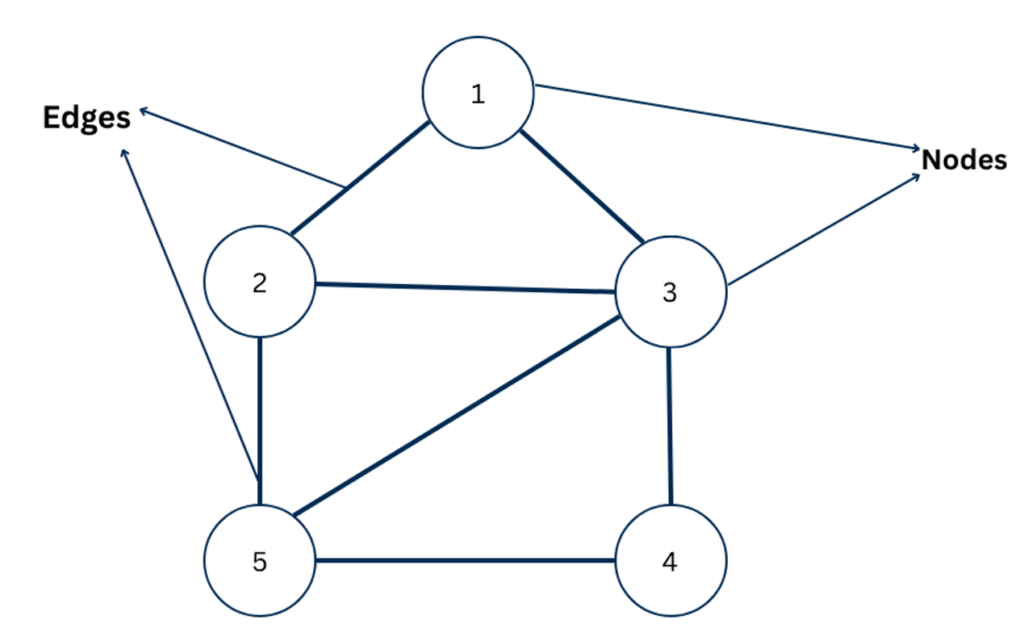
Node 1 is connected to 2 and 3. Node 2 is connected to 3 and 5, and so on. These connections represent relationships.
7. Tries
A trie (also called a prefix tree) is a tree-based data structure used to store and search strings, especially words.
Each node represents a single character, and the path from the root to a node forms a prefix of a word.
Tries are very efficient for prefix-based operations and are commonly used in:
- Dictionary searches
- Autocomplete systems
- Spell-checking applications
They allow fast searching, insertion, and deletion of words based on their prefixes.
Example:
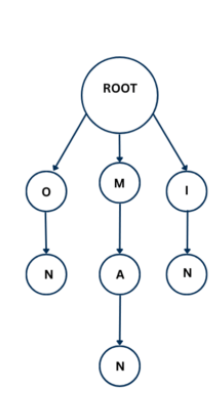
The trie shows branches forming the words “on”, “man”, and “in”. Each path forms a complete word.
8. Hash Tables
A hash table is a data structure that stores data in key–value pairs.
A hash function converts the key into an index (hash value), which is used to store and retrieve the corresponding value.
Because of this direct mapping, hash tables provide fast access, insertion, and search operations.
Hash tables are widely used in:
- Dictionaries and symbol tables
- Databases
- Caching systems
- Indexing
Example:
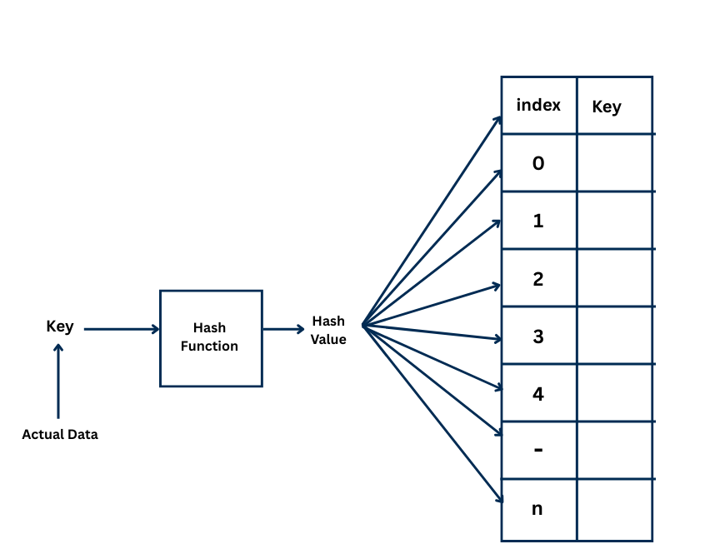
The hash function takes a key, computes a hash value, and stores the corresponding data at that index.
Why Do We Need Data Structures?
Data Structures are important because:
- They are used in every program or software system to organize data efficiently.
- They are fundamental to many efficient algorithms and help manage huge databases.
- Each data structure stores elements in a specific way in memory.
- They improve searching, insertion, deletion, and retrieval performance.
- Different problems require different data structures.
- They help with indexing and fast lookups (e.g., hash tables).
- They manage data in both main memory and secondary storage.
Areas Where Data Structures Are Used
- Numerical analysis
- Operating Systems
- Artificial Intelligence
- Compiler Design
- Database Management
- Networking
- Machine Learning
Applications of Data Structures
- Student Record Management System: Data Structures are used to store, search, and update student information like name, roll number, and marks efficiently.
- Database Management Systems: Data Structures such as trees and hash tables are used for fast data storage, retrieval, and indexing.
- Operating Systems: Data Structures are used in process scheduling, memory management, and file systems (e.g., queues, stacks, linked lists).
- Internet and Web Browsers: Stacks are used for undo/redo operations and for backward and forward navigation in web browsers.
- Compiler Design: Stacks and trees are used in syntax parsing, expression evaluation, and code generation.
- Social Media Applications: Graphs are used to represent user connections, and linked lists or trees are used to manage posts and feeds.
- Search Engines: Trees and hash tables are used for fast searching and indexing of web pages.
- Artificial Intelligence and Machine Learning: Data Structures like graphs, trees, and arrays are used to store and process large datasets efficiently.