Hashing is a method that turns a key into a smaller number called an index, which points to a location in a hash table where the data is stored. A hash function is used to do this conversion. This makes searching very fast because we can directly jump to the data’s location instead of checking multiple items. With hashing, search usually takes constant time O(1), no matter how large the data is. This is more efficient than linear search, which takes O(n), and binary search, which takes O(log n). That’s why hashing is one of the fastest techniques for searching.
What is hash function?
A hash function is a special formula or method that takes some input, like a name, number, or word (called a key), and turns it into a smaller fixed number. This number is called a hash value and is used as an address in a hash table where the data will be stored. The main job of a hash function is to make sure we can quickly find, insert, or remove data by directly jumping to its location instead of searching one by one.
What is hash value?
A hash value is generated by a hash function and indicates where a key should be stored in a hash table. In other words, the hash value acts as the index for the key, showing the exact position in the table where the corresponding data is kept
What is hash table?
A hash table is a data structure that stores data in the form of index-key pairs. It uses a hash function to calculate an index for each key, which determines where the corresponding value will be stored. Each position or index in the hash table is called a slot, where the index-key pair is kept for quick access.
Let’s see an example to understand hashing and hash table.
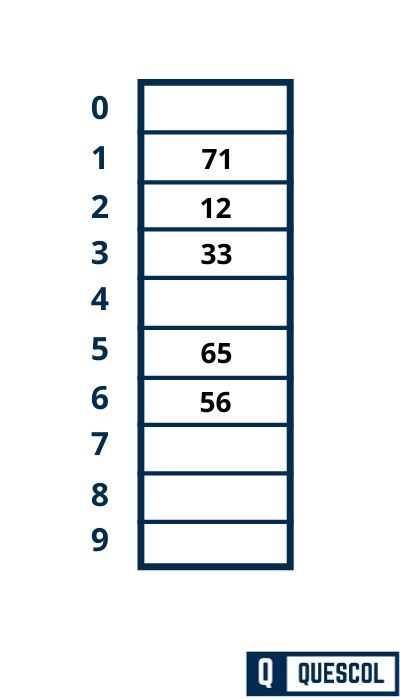
- The above figure shows a hash table and the size of the above hash table is 10.
- It means this hash table has 10 slots which are denoted by {0, 1,2,3,4,5,6,7,8,9}.
Now we have to insert value {12,56,33,65,71} into hashtable. So to calculate slot/index value to store items we will use hashing concept.
Where hash function will calculate this index value which is also known as the hash value.
Formula to calculate index / hash value
index/hash value = Key value % size of array
After computing hash values we can insert each value into the hash table.
Like if we have to insert 12 then index/hash value = 12%10 = 2.
So, 12 will be inserted at index 2 of the hash table shown above.
Load factor
In the above example, only 5 slots are filled and the rest is empty in a hash table which is referred to as the load factor. Load factor is denoted by lambda 𝜆
Formula to calculate load factor (𝜆) is
load factor(𝜆) = No. of items/table size.
= 5/10
Types of Hashing
- Open Hashing (Closed Addressing)
- Closed Hashing (Open Addressing)
Open Hashing (Closed Addressing)
In open hashing, if two or more elements get the same position, they are stored together in a linked list (or chain) at that position.
Example:
If two elements hash to index 3, then both are stored at index 3 in a linked list.
- Advantages:
- Simple and easy to implement.
- No problem of “table full,” as we can keep adding elements to the linked list.
- Works well when the number of collisions is high.
- Disadvantages:
- Needs extra memory for pointers in linked lists.
- Searching can become slow if too many elements are stored in one chain.
- More cache misses because of linked lists.
Closed Hashing (Open Addressing)
In closed hashing, all elements are stored inside the hash table itself. If a collision happens, we find another empty place in the table using different strategies (like linear probing, quadratic probing, or double hashing).
Example:
If index 3 is full, we move to the next index (say 4) until we find an empty spot.
- Advantages:
- No extra memory needed for linked lists.
- All data is stored inside the hash table, so it’s cache-friendly.
- Works well when the load factor (filled positions) is small.
- Disadvantages:
- If the table becomes full, no more insertions are possible.
- Performance decreases if the table is almost full (many collisions).
- Needs resizing if too many elements are added.
Time & Space Complexity
| Method | Best Case | Average Case | Worst Case |
|---|---|---|---|
| Open Hashing (Closed Addressing) | O(1) | O(1 + α) | O(n) |
| Closed Hashing (Open Addressing) | O(1) | O(1 / (1 – α)) | O(n) |
| Method | Space Complexity |
|---|---|
| Open Hashing (Closed Addressing) | O(n + m) (n = number of keys, m = table size for chains) |
| Closed Hashing (Open Addressing) | O(m) (table size only) |
Conclusion
Hashing is a technique used to store and find data quickly using a hash function. Sometimes, collisions happen when two values go to the same place. To solve this, we use methods like open hashing or closed hashing. Hashing is very fast and useful, but its performance depends on how collisions are handled and how well the hash function is designed.